

作者:MIT(麻省理工學院)節選
編譯:Felix, PANews
隨著 OpenAI 的 ChatGPT 等大型語言模型(LLM)産品被廣泛採用,來自全球各地的企業和人群幾乎每天都在使用 LLM。與其他工具一樣,LLM 也有其自身的優勢和局限性。
近日,麻省理工學院(MIT)發佈一項長達 206 頁的研究報告,探究在撰寫文章的教育情境中使用 LLM(如 ChatGPT)的認知成本,揭示了使用 LLM 對大腦及認知能力的影響。研究表明,過度依賴 OpenAI 的 ChatGPT 等人工智能聊天機器人可能會降低認知能力。
研究團隊將參與者分為三組:LLM 組、搜索引擎組、僅靠大腦組,這些參與者在 4 個月的時間内,使用指定工具(僅靠大腦組則不使用工具)在限定時間内撰寫文章,每次實驗中,文章的主題不同。團隊為每位參與者安排了 3 輪相同分組的實驗。在第 4 輪實驗中,團隊要求 LLM 組的參與者不使用任何工具(稱其為 LLM 轉大腦組),而僅靠大腦組的參與者則使用 LLM(大腦轉 LLM 組)。此次共招募了 54 名參與者參加前 3 輪實驗,其中 18 人完成了第 4 輪實驗。
研究團隊使用腦電圖(EEG)記錄參與者的腦電活動,以評估他們的認知投入和認知負荷,並深入了解在撰寫文章任務期間的神經激活情況。團隊進行了自然語言處理(NLP)分析,並在每次實驗結束後對每位參與者進行了訪談。團隊借助人類教師和一個 AI 評判員(專門構建的 AI 代理)的幫助進行了評分。
在自然語言處理(NLP)分析中,僅使用大腦的參與者在大多數主題的文章寫作方式上表現出很大的差異性。相比之下,LLM 組在每個主題上撰寫的文章在統計上趨於同質化,與其他組相比偏差明顯較小。搜索引擎組可能至少在一定程度上受到搜索引擎推廣和優化内容的影響。
LLM 組使用了最多的特定命名實體(NER),例如人物、姓名、地點、年份和定義;而搜索引擎組使用的 NER 數量至少少了 LLM 組的一半;僅使用大腦的組使用的 NER 數量比 LLM 組少了 60%。
參與 LLM 和搜索引擎小組的人員由於時間有限(20 分鐘)而承受著額外的壓力,因此更傾向於關注他們所使用工具的輸出結果。他們中的大多數人都專注於重復利用工具的輸出内容,從而一直忙於復制粘貼,而不是融入自己的原創想法,並從自己的視角和經歷出發對這些内容進行編輯。
在神經連接模式方面,研究人員使用動態定向傳遞函數(dDTF)方法測量參與者的認知負荷。dDTF 能揭示網絡相幹性的係統性和頻率特異性變化,對執行功能、語義處理和注意力調節具有重要意義。
腦電圖分析表明,LLM 組、搜索引擎組和僅靠大腦組在神經連接模式上存在顯著差異,這反映了不同的認知策略。大腦連接程度隨著外部支持的增加而係統性降低:僅靠大腦組表現出最強、最廣泛的網絡,搜索引擎組表現出中等程度的參與,而 LLM 輔助組的整體耦合最弱。
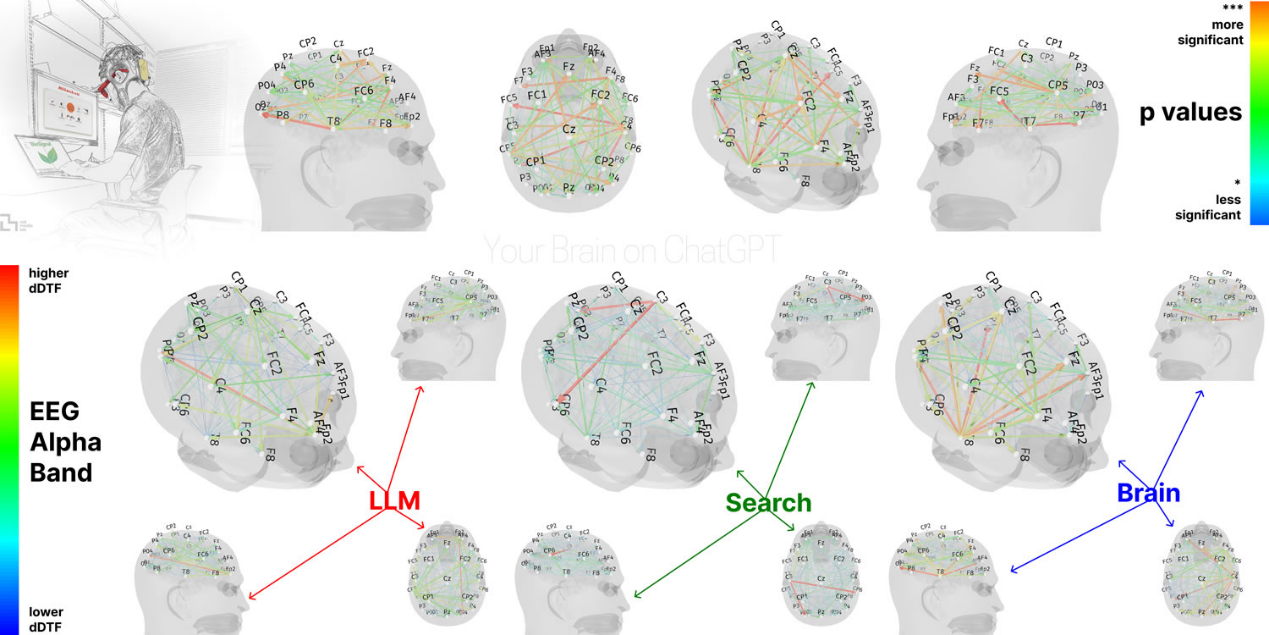
在第 4 輪實驗中,從 LLM 到僅靠大腦參與者表現出神經連接較弱,α 和 β 網絡參與度較低;而從僅靠大腦到 LLM 的參與者表現出更高的記憶回憶能力,並重新激活了廣泛的枕頂葉和前額葉節點。
在訪談中,LLM 組對其文章的歸屬感較低。搜索引擎組的歸屬感較強,但低於僅靠大腦的組。LLM 組在引用幾分鐘前自己所寫文章的能力方面也落後,超過 83% 的 ChatGPT 用戶無法引用幾分鐘前寫的文章。
這篇尚未經過同行評審的研究表明,在為期 4 個月的研究過程中,LLM 組的參與者在神經、語言、得分層面的表現都遜於僅使用大腦的對照組。隨著 LLM 在大眾中的教育影響才剛剛開始顯現,使用人工智能 LLM 可能實際上損害學習技能的提升,尤其是對於年輕用戶而言。
研究人員表示,在 LLM 被公認為對人類有益之前,需要進行「縱向研究」來了解人工智能聊天機器人對人類大腦的長期影響。
當詢問 ChatGPT 對這項研究的看法時,其回答稱:「這項研究並沒有說 ChatGPT 本質上有害——相反,它警告人們不要不加思考或努力地過度依賴它。」
相關閱讀:a16z:從AI代理、DePIN到微支付,加密與AI融合的11個關鍵落地方向
内容來源:PANews
財華網所刊載內容之知識產權為財華網及相關權利人專屬所有或持有。未經許可,禁止進行轉載、摘編、複製及建立鏡像等任何使用。
如有意願轉載,請發郵件至 content@finet.com.hk,獲得書面確認及授權後,方可轉載。

PANews是區塊鏈和Web3.0領域領先的智庫型信息平台,為行業用戶提供具有國際視野的前沿資訊與報告。PANews優質多元的内容以圖文、音頻、視頻等形式在全網多渠道覆蓋,包含推特、微博、抖音、視頻號等主流平台,旨在成為用戶的Web3信息官。PANews同時還是騰訊新聞的内容合作夥伴,内容被福佈斯、財新等媒體引用,獲得騰訊新聞、今日頭條、澎湃新聞等頒發的相關獎項。PANews的兩位聯合創始人均為福
 或
或 按钮分享
按钮分享